Lifetime of an Epsio View¶
Views are the lifeblood of Epsio. They allow users to define queries that Epsio will maintain on their behalf. Epsio continuously updates the results of these queries in a user-defined result table, ensuring they reflect the latest changes from the user's database. These updates are driven by incoming data from the CDC Forwarder, which streams changes from the user's database.
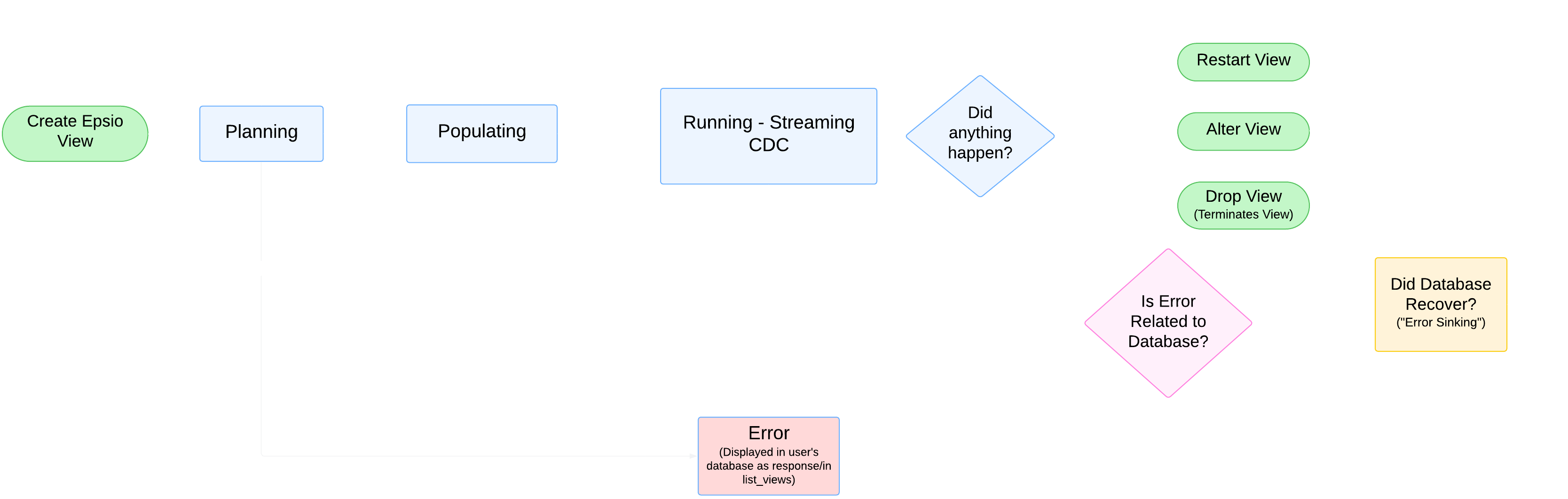
The complete flow chart for a view's lifecycle is as follows:
 A view is defined by a user by calling a procedure in their database,
A view is defined by a user by calling a procedure in their database, epsio.create_view('<view_name>', 'SELECT ...'). This command is forwarded to the Execution Engine via the Commander, where the planning will begin. Once the planning finishes successfully, views enter an initial phase called "population".
Population¶
During the population phase, the view will push down any projections and filters in order to bring the least amount of data possible from the user's database. It will also concurrently take an atomic snapshot to ensure CDC arriving will not be duplicated (or missed).
For example, in Postgres, consuming the initial data is done by running COPY FROM ... WHERE .... The atomic snapshot is done by running pg_current_snapshot in the same transaction, which returns the minimum XID in the database, the maximum, and the ones in progress. Any CDC event received from the forwarder will be filtered accordingly (ensuring it is not before minimum XID, is after max XID, or is between them and not in in-progress XIDs) to ensure no event is missed/duplicated.
Once the population is finished (the Sink receives a TimeEnd message), all diffs are written in parallel to a temporary table in the user's database by the Sink (after being consolidated). Upon finishing this, the view will change the temporary table's name to be the correct name, so that there will never occur a time in which the result table is created without the correct results.
If data already exists in the source database, the Sink knows to remove rows which should not exist and insert necessary ones, never performing unnecessary actions. This is done in one transaction to ensure result integrity.
Running¶
Once population finishes, the view enters the running phase. During this phase, the view receives diffs from the CDC Forwarder, and runs them through its collections. Each collection receives diffs and output diffs; collections never perform full recalculations, but instead hold state allowing them to quickly stream the diffs through them.
By default, in order to maintain high throughput, views begin by batching together transactions that arrive in the same 50ms. If it cannot handle the throughput, it will grow the batch sizes until it can (and appropriately the latencies shown in epsio.list_views() will reflect this).
The Sink (which writes to the user's database) always consolidates all diffs before sinking them to the user's database in order to minimize stress on the user's database. In contrast to comparable methodologies, this is not only done in memory; if a transactions output is extremely large (for example, 50GB of diffs), the Sink holds a consolidated RocksDB backed state which is filled by the diffs, and then subsequently drained.
Errors¶
Views are built to be fault-tolerant; if errors occur on the database side, the view will enter an error sinking phase, and will continuously try to recover until the issue is fixed (for example, if the database is restarted, it will wait till the database is up and running). If however, an error occurs that is not on the database side (for example, if there is an internal error), the view will automatically go back to the populating phase.