Execution Engine - Epsio¶
Epsio's execution engine's main responsibility is to plan and maintain results of views (pre-defined queries with names). Each view receives changes from the forwarder and streams them through its internal operators, until finally the changes reach the sink, where they are consolidated and written to the user's database (this is done continuously until either terminated because of a user action or an error that is unrecoverable). The view operators heavily rely on intermediate states which allow them to efficiently stream changes through them, without ever performing full recalculations.
Planning the Dataflow¶
To create a view, users run the epsio.create_view('<view_name>', 'SELECT ... '); command on their database. This command is forwarded to the execution engine via the Commander, where the planning will begin. Epsio's planning takes several steps:
- Break down the query into an AST (abstract syntax tree).
- Create a logical plan from the AST. This plan defines what high-level steps logically need to take place (such as
JOIN,GROUP BY, etc). If we ran
CALL epsio.create_view('my_view', 'SELECT count(*) FROM example_table e JOIN numbers_table n ON e.b = n.a WHERE e.b > 30')
the unoptimized plan would look something like this:
Projection: COUNT(*)
Aggregate: groupBy=[[]], aggr=[[COUNT(*)]]
Filter: e.b > Int64(30)
Inner Join: Filter: e.b = n.a
SubqueryAlias: e
TableScan: example_table
SubqueryAlias: n
TableScan: numbers_table
Aggregate: groupBy=[[]], aggr=[[COUNT(*)]]
Inner Join: e.b = n.a
SubqueryAlias: e
Filter: example_table.b IS NOT NULL AND example_table.b > Int64(30)
TableScan: example_table projection=[b], partial_filters=[example_table.b > Int64(30)]
SubqueryAlias: n
Filter: numbers_table.a IS NOT NULL AND numbers_table.a > Int64(30)
TableScan: numbers_table projection=[a], partial_filters=[numbers_table.a > Int64(30)]
4. Convert the logical plan into a physical plan, and run physical optimizations, such as grouping multiple operations together. The total physical plan is a graph of nodes, with the sink (the node that is responsible for sinking back into the user's database) always being the last. Each node is called a Collection; there are ~15 types of Collections.
Executing a View¶
The final stage when planning a view is to convert the logical plan (built from the query) into a physical one. This physical plan is essentially a graph of nodes, with the final node being the sink node (the node that is responsible for sinking back into the user's database). These nodes are called Collections. Each Collection is responsible for doing a certain operation, and then transferring relevant changes (referred to internally as diffs) to the next collection. For example, the above view
CALL epsio.create_view('my_view', 'SELECT count(*) FROM example_table e JOIN numbers_table n ON e.b = n.a WHERE e.b > 30')
would be planned out into a series of collections roughly like this:
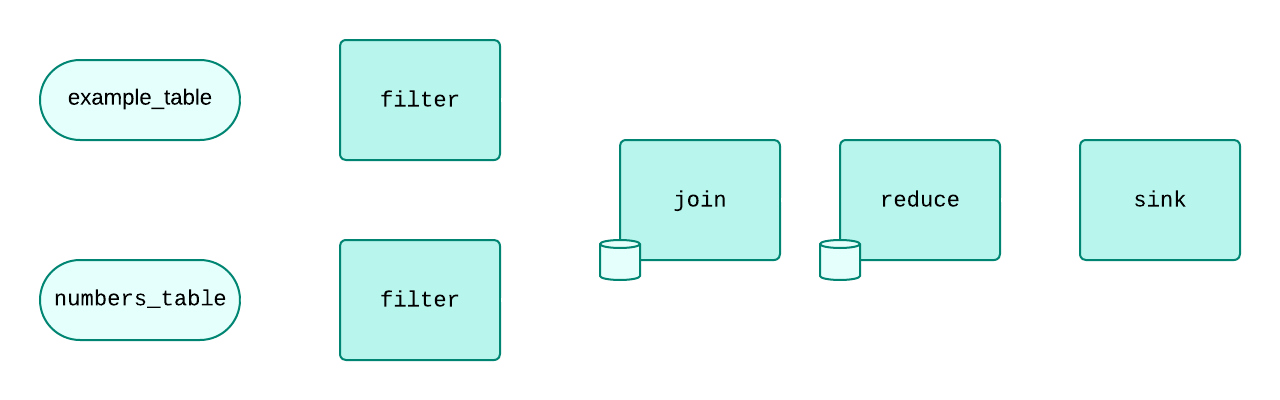
Stateful vs Stateless Collections¶
Some collections are stateless, while others are not. A collection only holds state if necessary in order to stream diffs efficiently- in the above diagram, as can be seen with the "database" icons, only the reduce and join collections hold state. The join collection, which is responsible for JOINing two collections based on an equivalent key, has a state which holds mappings of each input's keys to their respective values. When a diff comes in on one side, the JOIN collection looks to the state it holds on the other side and finds the equivalent diffs which need to be "joined" to it. The reduce collection, which is responsible for aggregating incoming diffs and outputting aggregated diffs, holds the state of all aggregations. In the above example, the reduce collection would hold a single value- the total count. Upon receiving a diff, it would either subtract or add from the total count, and then output a diff removing the old count, and another diff adding the new count.
A filter collection, conversely, does not need to hold any state in order to filter out incoming diffs. Another such collection which does not require state is map (a collection whose job is to map one diff to another, for example projecting columns).
All stateful collections in Epsio are based on a highly optimized fork of RocksDB. Each stateful collection has its own RocksDB state, and each state is uniquely configured to work efficiently for its collection.
Execution of Collections¶
Epsio opens several threadpools, based on Tokio, Rayon, and RocksDB regardless of the number of views:
- An AsyncIO threadpool, with threads equal to the amount of CPUs, for non CPU intensive tasks which need to be executed with extremely low latency regardless of CPU pressure. Tasks in this thread will often open other tasks and
awaitthem (giving room for other tasks to run on these threads until the opened tasks finish)- meaning these threads should usually be available. - A threadpool for CPU intensive tasks (with threads also equal to the amount of CPUs), such as sorting diffs or consolidating diffs together.
- A threadpool for IO tasks. This threadpool usually has roughly 512 threads regardless of the amount of CPUs.
- Internal RocksDB threadpools, which are used for flushing memory to disk, compactions, and more.
Each collection creates a task which is run in the first threadpool (the AsyncIO threadpool). When a collection receives diffs, it opens tasks in the two other threadpools, and awaits them. Collections are highly parallelized and break down the job they need to do into many tasks; if there exist enough threads available in the threadpool to run all the tasks, a single Collection will fully utilize all resources available. If not, the Collection's tasks may simply run sequentially on the same thread. Because of many optimizations done in rayon, most CPU intensive work will still take advantage of thread locality if possible.
Transferring Messages between Collections¶
Epsio views are transaction consistent, never showing intermediate results. Transactions can be batched together if they arrive at the same time, to ensure high throughput (the default is batching collections every 50ms). Each collection can receive two types of messages:
Diffs- a micro-batch of DiffsTimeEnd- An end to a given series of transactions.
When a collection has processed all diffs and receives a TimeEnd, it is consistent transactionally with the user's database. For joins (or any other collection with more than one input), it must receive TimeEnds from all inputs before it considers a time "done".
For example:
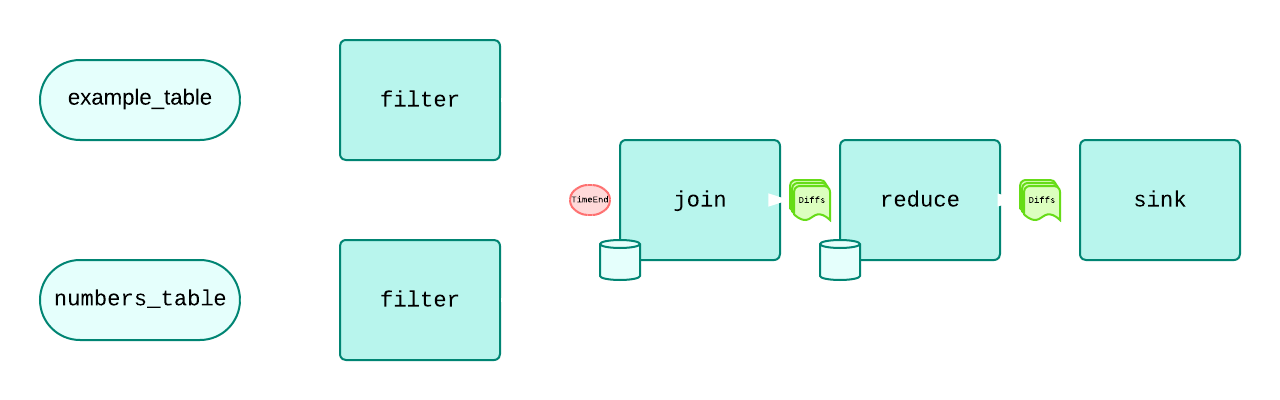
In the above diagram, there are three messages going through- two Diff batches, and one TimeEnd. The Sink will receive diffs and consolidate them with each other, but only upon receiving a TimeEnd will it sink all received diffs into the user's database.
There are two different ways to transfer messages:
- Mmap based buffers - Buffers are created between the sending and receiving collection. Each collection coordinates with a centralized Memory regulator to pull a safe amount of diffs from the buffer, and then processes the micro-batch of diffs.
- Synchronously - The collection receives the next collections operation as a
callback, and simply runs it on each outputted diff. This is common for stateless operations such asfilterormap, where the cost of having a buffer is not worth the ability to run asynchronously to the next operation.