Epsio Key Concepts¶
Incremental Views¶
Epsio's views are very similar to traditional SQL views in that they represent a query- but unlike a traditional SQL view, Epsio's views are both incremental and materialized.
This means that:
- Query results are always persisted; no additional computation needs to be done when the view is queried.
- The view is updated incrementally as the underlying data changes, meaning that the view is always up to date without ever needing to run the complete query again.
Epsio does this by taking the view's query and building a streaming "pipeline" that every new change goes through. The pipeline is essentially a series of stateful "operators" connected to each other, each doing a specific manipulation on the change and passing on corresponding changes.
Query planning¶
Query planning in Epsio is very similar to planning in traditional databases. For Epsio to understand how to incrementally maintain the results of a view, it needs to parse the SQL of a new view and build a dataflow graph that represents the stages of calculating and maintaining the result of it’s query.
For example, the following view:
CALL epsio.create_view('my_view', '
SELECT item_id, AVG(cs_quantity) agg1
FROM catalog_sales
JOIN promotion ON cs_promo_sk = p_promo_sk
WHERE (promotion.p_channel_email = ''N'' OR promotion.p_channel_event = ''N'')
GROUP BY item_id');
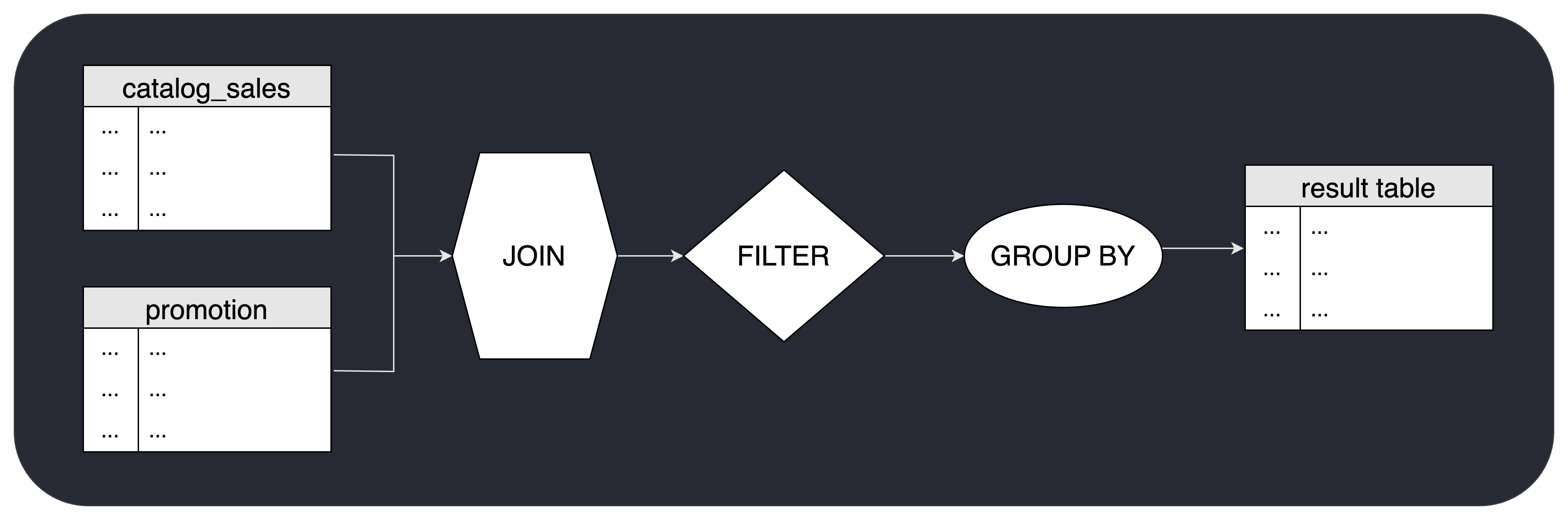
In contrast to traditional databases, each stage in the graph is not only responsible for outputting the initial result, but also understanding how later received changes affect the original result of that stage and passing on the corresponding changes to the next stage in the graph.
In addition to building a basic dataflow graph, the Epsio planner is also responsible for optimizing the graph to reduce the amount of work needed to maintain the view. For example, if a view contains a filter clause, the planner will try to push the filter operation as close to the base tables as possible to reduce the amount of data that needs to be processed by the rest of the graph.
Execution Engine¶
After a query plan is built, Epsio's Rust-based execution engine is responsible for streaming changes that are made to the base tables throughout the data flow graph and updating the view's result accordingly.
Epsio's execution engine is:
Highly parallel¶
The execution engine not only runs each stage of the dataflow graph in parallel but can also "split the work" of a single dataflow stage into multiple workers if needed.
Built to work in "micro batches"¶
Since many changes streamed through the dataflow graph can be consolidated into a single change, the execution engine works in a "micro-batch" mechanism, where it collects changes for a few milliseconds and then tries to consolidate the collected changes together. This allows not only to reduce the amount of processing power Episo requires but also reduces the write-back load on the database when writing and updating the view's result.
For example, if a view for the query SELECT COUNT(*) FROM base_table received 5 new inserts to base_table in a single batch, Epsio will consolidate the 5 inserts together and stream a single +5 change thoughout the dataflow graph instead of 5 separate +1 changes, and will update the result view only once.
Stateful¶
The Epsio execution engine saves state information to be able to update old query results without re-querying the database.
For example, to incrementally maintain the results of a SELECT COUNT(*) ... GROUP BY ... query, Epsio will need to internally save the count of rows per group. This way, when a new row is added, Epsio simply adds to the old saved count without querying the database for the previous result.
The state information that each stage saves depends on the specific SQL operators used. For example, GROUP BY saves the group keys and the corresponding aggregated values. JOIN saves the join key and all the corresponding rows from each side of the JOIN, etc...
To ensure Epsio doesn't have a high memory footprint, state information is saved on a disk, with an in-memory cache. All access to the disk is done with Async IO to ensure high parallelism and throughput.
State Management¶
Epsio uses a combination of in-memory caching and disk storage to manage its state information. Epsio's on-disk storage layer is based on a combination of RocksDB and a proprietary key-value store that is optimized for Epsio's use case.
Both RocksDB and Epsio's proprietary key-value store compress data before writing to disk to reduce the amount of disk space used.
Change Data Capture¶
To capture changes made to the base tables, Epsio uses CDC (Change Data Capture) mechanism for each supported database. For example, for PostgreSQL, Epsio uses logical replication, in MySQL it uses binlog, and in SQL Server it uses Change Data Capture.
Eventual Consistency¶
Eventual Consistency
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Wikipedia
When underlying data is changed in a query defined in Epsio, the change might not be immediately reflected in Epsio. However, the incremental update process ensures that Epsio will eventually be consistent with the data. This might result in brief periods (usually only a few milliseconds) where the view lags slightly behind the latest state of the data.